Process scheduling in the Linux kernel.
Process scheduling
In modern systems, there are usually many processes that are in TASK_RUNNING state, which means they are ready to run.
It is the kernel's job to decide which process to run, and how long to run it.
This is done by the kernel scheduler, a kernel subsystem that is responsible for scheduling the processes.
Most modern operating systems, including Linux, employs preemptive multitasking. In this model, each process is assigned a slice of CPU time to run, then it will be preempted by the kernel scheduler. The scheduler then decides which process to run next, and how long its time slice will be. A process can also relinquishes its CPU slice, for example when a process need to wait for a resource to become available. The scheduler also needs to select the next process if this happens.
When a processor changes to a new process, the scheduler is responsible for saving the state of the previous process,
including the registers (including the program counter) and the memory address space.
This is often referred to as the context of a process, thus switching from one process to another is called context switch.
What to consider when scheduling
The processor scheduler runs every time the system needs to decide which process to run. Each time it runs, the input is a given set of runnable processes, and the output is the process to run next. In a scheduler design, many things need to be considered.
- Process type
Processes can be classified into two types: I/O-bound or CPU-bound.
Most desktop GUI applications are I/O-bound, because they spend most of their time waiting for user input or output. These processes usually do not run for long periods of time, and tends to stop running voluntarily to wait for I/O events. Conversely, CPU-bound processes tend to spend much of their time executing code, until they are preempted by the kernel scheduler.
However, I/O-bound processes are often latency-sensitive, which means they often require a quick response time, since otherwise users may be waiting for a long time for the application to respond. While CPU-bound processes usually do not expect to be responsive.
- Priority
A common way to rank processes is to give them a priority. Ideally, a process with a higher priority runs before a lower priority, or runs for a longer time than a lower priority.
- Speed
Since Linux kernel 2.5, a new scheduler named O(1) scheduler is introduced.
It can perform its work in constant time, which is a big improvement over the previous O(n) scheduler.
- Latency and throughput
The scheduler in the system needs to consider both high throughput and fast response time.
The O(1) scheduler has some issues when it comes to latency-sensitive tasks.
It is ideal for large server workloads, which lack of interactive processes, but performed poorly on desktop systems.
Since Linux kernel 2.6.23, the Completely Fair Scheduler (CFS) replaces the O(1) scheduler to improve the interactive performance.
- Real-time requirement
There might also be real-time processes, which need to run before a certain deadline. And the kernel scheduler also need to consider the real-time requirement.
Scheduler classes
The Linux kernel uses modular schedulers to support different types of processes. This is implemented by the scheduler class approach.
A scheduler class implements a specific scheduling algorithm for a certain process type.
For example, we have the real-time scheduler class rt_sched_class for real-time processes,
and the CFS scheduler class fair_sched_class for normal processes.
The scheduler classes have priorities, and they are chained together in the order of priority. The kernel uses a core scheduler to iterate over the scheduler classes, and uses the result of the first scheduler class that produces a valid scheduling decision.
In the source code I am working on (linux-next commit: 09688c0166e7),the scheduler classes are ordered by
the linker script: ./include/asm-generic/vmlinux.lds.h (Line 127 in commit 09688c0166e7).
#define SCHED_DATA \
STRUCT_ALIGN(); \
__begin_sched_classes = .; \
*(__idle_sched_class) \
*(__fair_sched_class) \
*(__rt_sched_class) \
*(__dl_sched_class) \
*(__stop_sched_class) \
__end_sched_classes = .;
Scheduler class instances are defined in separate files in the ./kernel/sched/ directory.
For example, CFS scheduler class is defined in ./kernel/sched/fair.c (Line 11735 in commit 09688c0166e7).
The helper macro DEFINE_SCHED_CLASS helps to align the scheduler instances to guarantee the layout in memory.
DEFINE_SCHED_CLASS(fair) = {
.enqueue_task = enqueue_task_fair,
.dequeue_task = dequeue_task_fair,
// ...
.pick_next_task = __pick_next_task_fair,
.put_prev_task = put_prev_task_fair,
.set_next_task = set_next_task_fair,
// ...
.task_tick = task_tick_fair,
// ...
.update_curr = update_curr_fair,
// ...
};
A scheduler class contains a set of methods that implement the scheduling algorithm.
Important ones are enqueue_task(), dequeue_task(), pick_next_task(), put_prev_task(), task_tick(), etc..
The core scheduler iterates over scheduler classes by using the for_each_class macro in ./kernel/sched/sched.h,
which iterators over the SCHED_DATA from the __end_sched_classes to the __begin_sched_classes in ./include/asm-generic/vmlinux.lds.h.
You can find the uses of for_each_class in ./kernel/sched/core.c (Line 5633 in commit 09688c0166e7).
for_each_class(class) {
p = class->pick_next_task(rq);
if (p)
return p;
}
BUG(); /* The idle class should always have a runnable task. */
The scheduler body
The function __schedule() in ./kernel/sched/core.c (Line 6182 in commit 09688c0166e7) is the main body of the Linux scheduler.
What this function does includes:
- Put the previously running task into a run queue and pick up a new task to run next (in
pick_next_task()); - Call
context_switch()function to actually switch to the new task;
static void __sched notrace __schedule(unsigned int sched_mode)
{
// ...
cpu = smp_processor_id();
rq = cpu_rq(cpu);
prev = rq->curr;
// ...
next = pick_next_task(rq, prev, &rf);
// ...
if (likely(prev != next)) {
rq->nr_switches++;
// ...
RCU_INIT_POINTER(rq->curr, next);
// ...
rq = context_switch(rq, prev, next);
// ...
}
// ...
}
In the function body above, the rq returned from the cpu_rq(cpu) call is called a run queue.
Ready threads are enqueued into run queues by the scheduler.
Each CPU has its own run queue, and one ready thread belongs to a single run queue at a time.
You can find the run queue data structure defined in the ./kernel/sched/sched.h (Line 926 in commit 09688c0166e7).
The pick_next_task() calls the __pick_next_task() function in ./kernel/sched/core.c line 5603 (in commit 09688c0166e7),
which uses the for_each_class macro to iterate the scheduler classes to find the next task (Code in line 5633 showed in the above section).
Similarly, the pick_next_task() function also calls the put_prev_task() defined in ./kernel/sched/sched.h (Line 2188 in commit 09688c0166e7),
which actually delegates the work to the scheduler class of the previous task:
static inline void put_prev_task(struct rq *rq, struct task_struct *prev)
{
WARN_ON_ONCE(rq->curr != prev);
prev->sched_class->put_prev_task(rq, prev);
}
The __schedule() function is called whenever there is a need to reschedule tasks.
For example after interrupt handling, or when a task calls sched_yield() to relinquish the CPU.
There is also a function scheduler_tick() which is called periodically by the kernel to check if a task is running for too long.
The CFS scheduler
Since Linux kernel 2.6.23, the Completely Fair Scheduler (CFS) is the default scheduler for normal processes.
The main idea behind the CFS is to maintain balance of processor time among tasks. This means processes should be given a fair amount of the processor. When one or more tasks are not given a fair amount of time relative to others, then those out-of-balance tasks should be given time to execute.
To achieve this, the CFS maintains the amount of time a given task has used in a concept called virtual runtime
(vruntime in ./kernel/sched/sched.h line 547 in commit 09688c0166e7).
The smaller a vruntime is, which means the task has been assigned less CPU time, the higher its priority in the next rescheduling process.
The Linux kernel uses a red-black tree to maintain processes by the virtual runtime
(rb_node in ./kernel/sched/sched.h line 541 in commit 09688c0166e7).
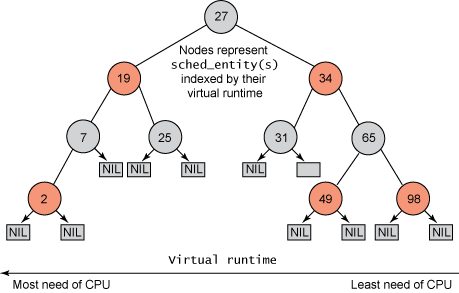
In CFS, the task with the smallest vruntime is the next task to run. The vruntime of a process is calculated based on the priority of the process.
Process priority
The Linux kernel scheduler uses two different types of priority: the real-time priority, and the nice value.
Real-time priority
A real-time priority is a number from 0 to 99 by default, and higher real-time priority means higher priority. The real-time priority is used by the real-time scheduler. It is optional to set a real-time priority for a process, and all real-time processes are at a higher priority than normal processes.
You can check the real-time priority of a process by the RTPRIO column in the ps or top command.
If the value is -, it means the process is not real-time.
Nice value
A nice value is a number from -20 to 19, where -20 is the highest priority and 19 is the lowest priority, and 0 is the default priority.
Note that larger nice value means lower priority, as the process is being 'nice' to other processes.
You can see the nice value of a process by using the ps or top command and checking the NI column.
There is also a nice command that can be used to set the nice value of a process.
Each nice value is mapped to a weight value, which is used by the CFS to calculate vruntime.
The nice to weight map is defined in the ./kernel/sched/core.c file (Line 10895 in commit 09688c0166e7).
const int sched_prio_to_weight[40] = {
/* -20 */ 88761, 71755, 56483, 46273, 36291,
/* -15 */ 29154, 23254, 18705, 14949, 11916,
/* -10 */ 9548, 7620, 6100, 4904, 3906,
/* -5 */ 3121, 2501, 1991, 1586, 1277,
/* 0 */ 1024, 820, 655, 526, 423,
/* 5 */ 335, 272, 215, 172, 137,
/* 10 */ 110, 87, 70, 56, 45,
/* 15 */ 36, 29, 23, 18, 15,
};
And the vruntime is calculated as:
$$ vruntime=(actual\;runtime) * \frac{(weight\;of\;nice\;0)}{process\;weight} $$
In the kernel source, the vruntime is updated in the update_curr() function,
which in the CFS scheduler is the update_curr_fair() (Line 884 in ./kernel/sched/fair.c),
which in turn calls its own implementation of update_curr() in line 844.
When the CFS reschedule function is called, it calls the pick_next_task_fair() to choose the next task
(Line 7213 in ./kernel/sched/fair.c),
which calls a subroutine pick_next_entity() (Line 4506) to do the actual work.
static struct sched_entity *
pick_next_entity(struct cfs_rq *cfs_rq, struct sched_entity *curr)
{
struct sched_entity *left = __pick_first_entity(cfs_rq);
struct sched_entity *se;
// ...
se = left; /* ideally we run the leftmost entity */
if (cfs_rq->skip && cfs_rq->skip == se) {
struct sched_entity *second;
// ...
if (second && wakeup_preempt_entity(second, left) < 1)
se = second;
}
if (cfs_rq->next && wakeup_preempt_entity(cfs_rq->next, left) < 1) {
// ...
se = cfs_rq->next;
} else if (cfs_rq->last && wakeup_preempt_entity(cfs_rq->last, left) < 1) {
// ...
se = cfs_rq->last;
// ...
return se;
}
